OpenAI Chat GPT Monetization
This pricing template will discuss how to model OpenAI’s pricing to calculate internal costs, and how to create a customer-facing pricing plan on top of this usage to monetize generative AI services in your own product. Usage of the service is metered and customers only pay for what they use. For more information on OpenAI pricing, read here.
How it works
Since releasing ChatGPT for public use in late 2022, there has been an explosion in usage and interest in generative AI technologies. This was accelerated when OpenAI made its large-language models available to developers via API, allowing them to leverage generative AI services in their own products as well.
To support this model, OpenAI uses a prepaid usage-based model. All actions (input comprehension and output generation) are priced in Tokens. Usage is metered and tracked, then the cost of each interaction with the model is calculated.
Pricing is based on a few different vectors; first the model type itself. We will walk through how to build out pricing for both GPT 4 and GPT 3.5 Turbo. Within each model, pricing also depends on the model context (ie. 8K or 32K). See the screenshot below from OpenAI’s pricing.
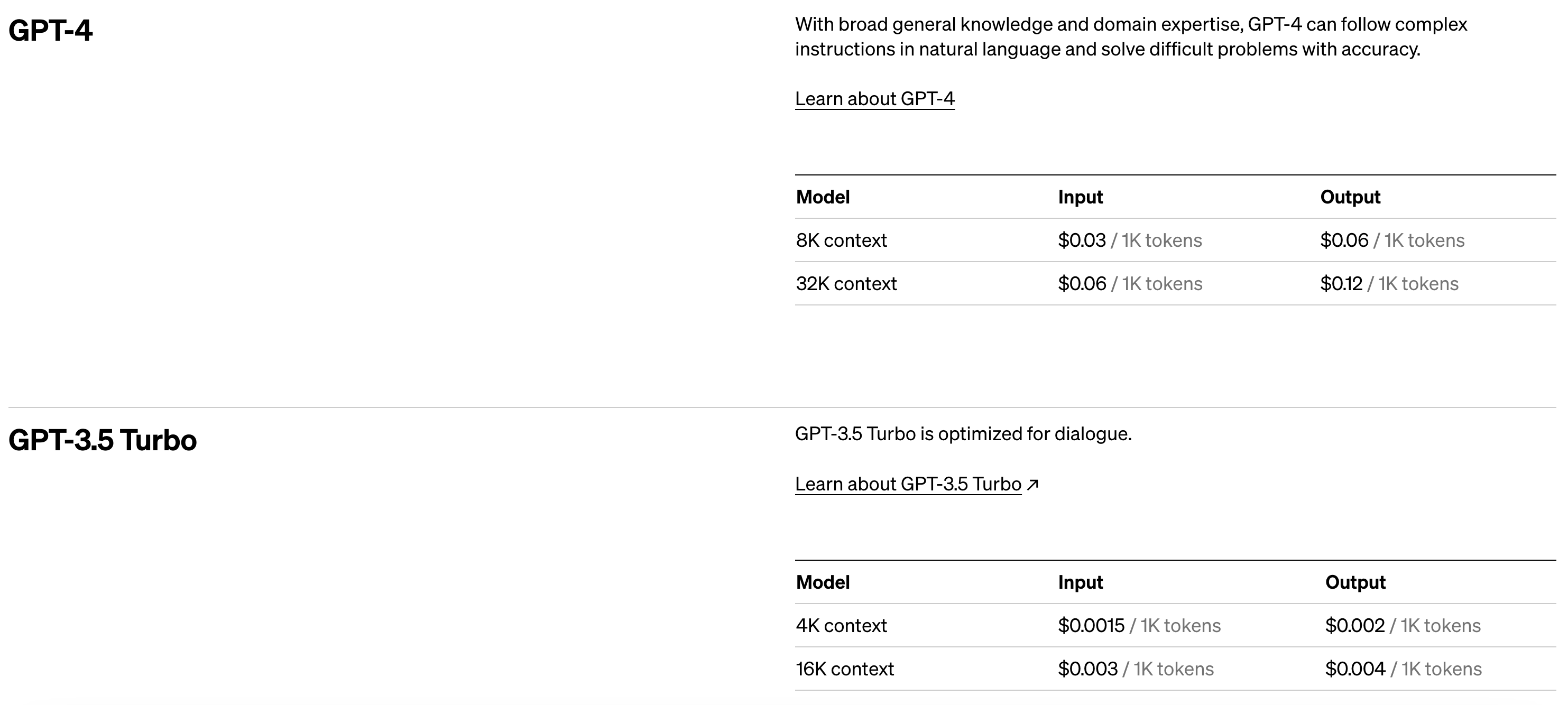
Instructions
We will walk through how to re-create this pricing model in Amberflo. If you do not yet have an Amberflo account, but would like to get started, please reach out to us here.
Step One - Create meters to track the token consumption on both chat inputs and outputs
A chat interaction is broken down into two parts: the user-provided input which the model needs to ‘interpret’ in order to generate a prompt, and the LLM-provided output based on the prompt. Both the length of the prompt and the output should be tracked and charged.
All usage and billing calculations for OpenAI are done in terms of tokens. Each token can have a different rate depending on the context, model type, and input/output.
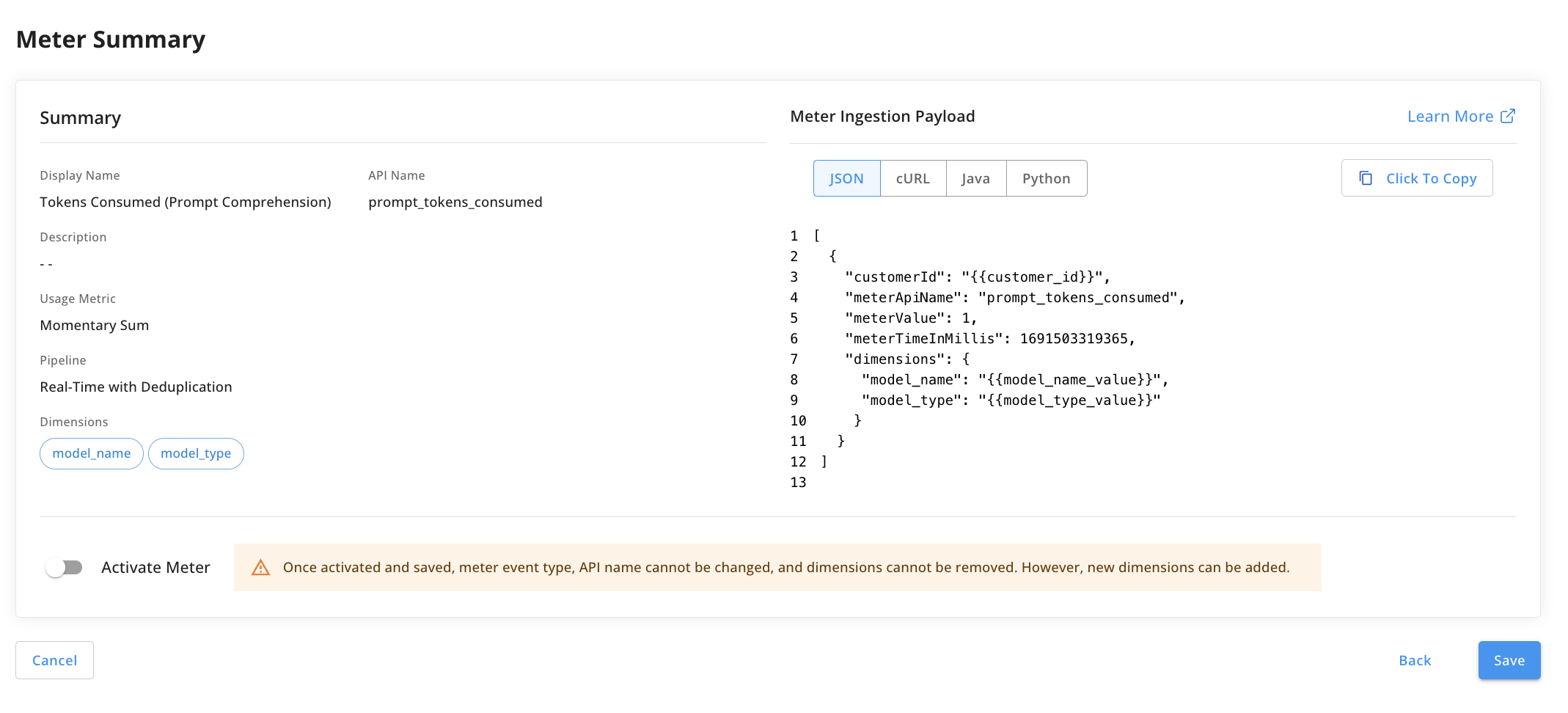
First, we need to create a meter that tracks the number of tokens consumed by the input (prompt comprehension). Since OpenAI tracks this for each interaction, we can connect our meter to this API to obtain the value.
We can create a standard sum meter to track this; the meter value for each event will be the number of tokens consumed by that input. Note that the dimensions include the model name (GPT 4 or GPT 3.5 Turbo), and the model type (context). See the screenshot below for the meter setup:
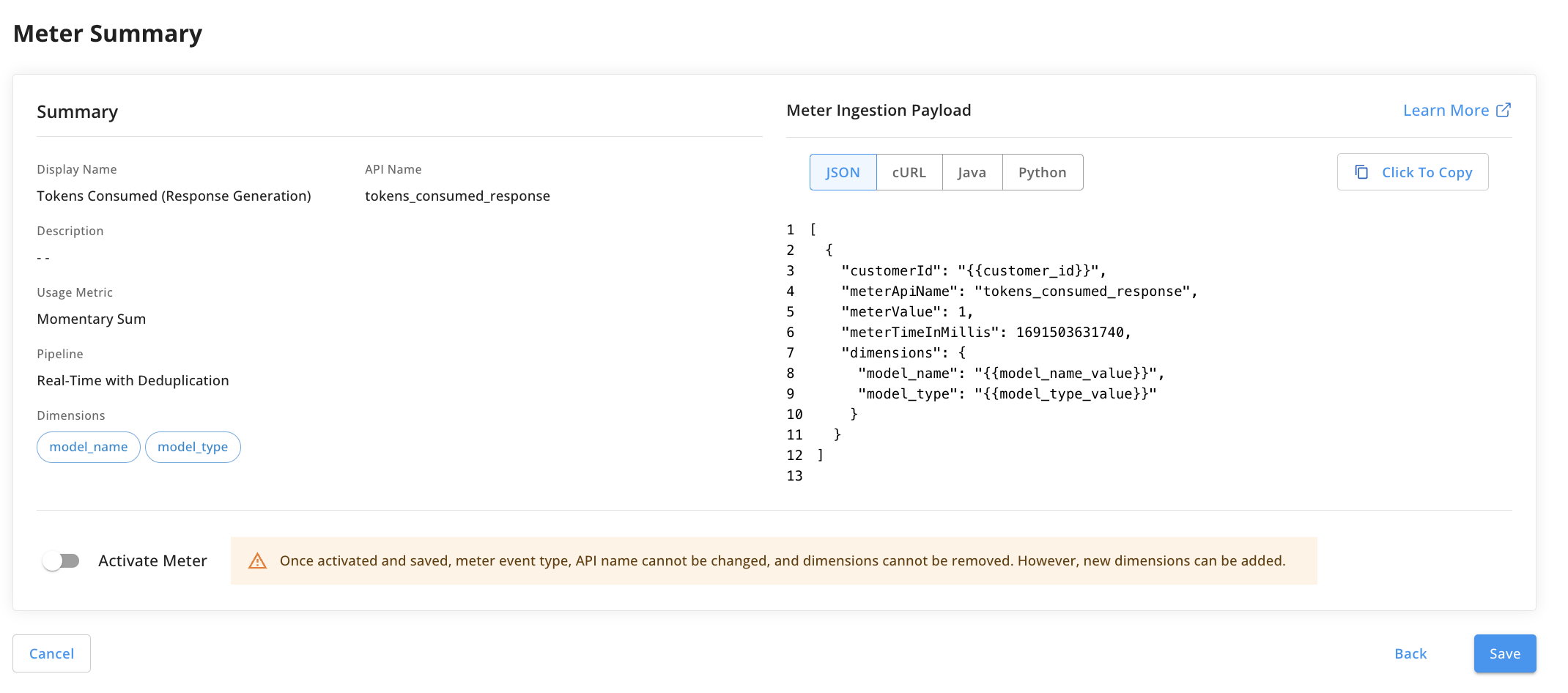
Next, we will repeat the process and create a meter that tracks the tokens consumed from the model output as well. This will also be a sum meter and the meter value will correspond to the number of tokens consumed for each output generated. The same dimensions for model type and model name will be used. See the screenshot below for setup:
Note that when creating both meters, you can select the checkbox to automatically create a corresponding product item with each meter. Product items are used in the billing service to assign a charge to usage.
Step Two - Deploy the meters to track real-time usage
Each time a chat interaction takes place, corresponding meters will be sent to Amberflo with the number of tokens consumed for the input and output.
The meter payload format is shown in the screenshots above. This is the event structure that Amberflo receives.
There are several options for integrating your solution with Amberflo to ingest usage to the metering system. We provide SDKs in several common languages; an ingestion API; and we enable meter ingestion from files, databases, and other common tools including:
- AWS CloudWatch
- AWS S3
- AWS SQS
- Elastic Logstash
- MongoDB
- Databases and JDBC
- Files
- POSTMAN collections
- Kong API gateway
For step-by-step walkthroughs on how to use each ingestion method, please refer to our documentation:
Here is the SDK information: https://docs.amberflo.io/recipes
Here is the API reference: https://docs.amberflo.io/reference/post_ingest
Here are the docs on other ingestion options: https://docs.amberflo.io/docs/cloudwatch-logs-ingestion-1
Once the meter ingestion pipeline is configured, usage will be tracked and aggregated (by customer and by all custom dimensions you included) in real time. You can visualize and query the usage data from the moment it is ingested.
Step Three - Create the usage-based pricing for GPT 4 and GPT 3.5 Turbo
Once the meters are created, the next step is to create the customer-facing pricing. These are the rates that you will charge your customers for using the generative AI service in your product. Amberflo allows you to track and analyze usage, model your internal costs from OpenAI, and monetize the service with customer-facing pricing all from inside the same tool.
First, we will create the pricing plan. Select Billing -> Pricing Plans -> Create New.
The plan will have two product items, the input comprehension tokens and the output generation tokens. For each, we will use the Per Unit with Dimensions rate model.
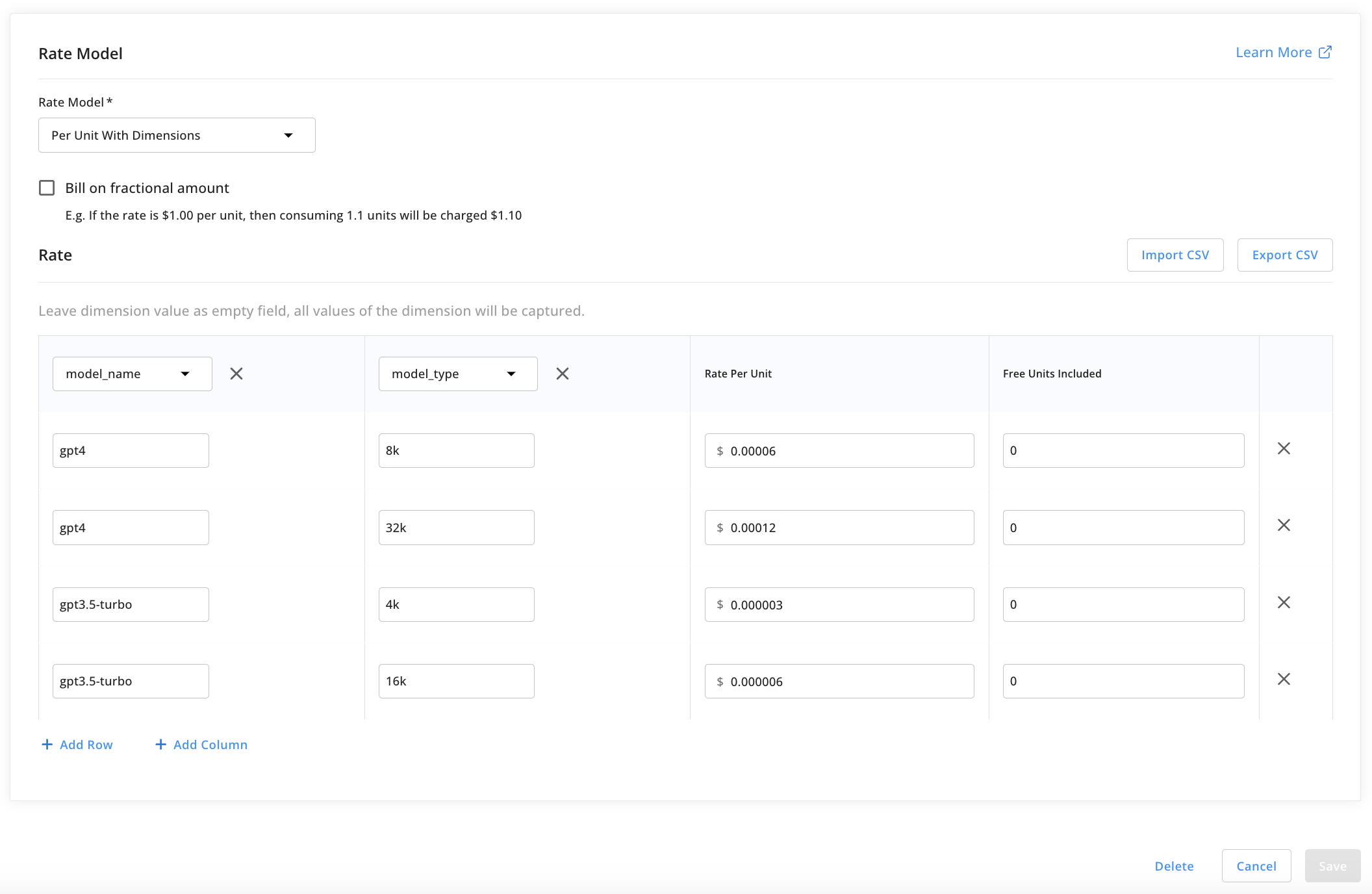
We will repeat this step to add pricing for the output generation as well.
Note that since this is the customer-facing pricing plan, the per-token rates should be higher than those from OpenAI. This pricing should include a premium for the value added which allows your business to cover its costs and turn a profit.
Step Four - Activate the plan and assign customers to begin invoicing
To begin generating invoices for usage, you must activate the pricing plan and assign the plan to customers. From the moment the plan is assigned, the billed amount will be calculated in real-time as usage occurs by applying the product item rates.
You can view the on-demand invoice at any point during the billing cycle by navigating to the customer view and selecting the invoice you’d like to view.
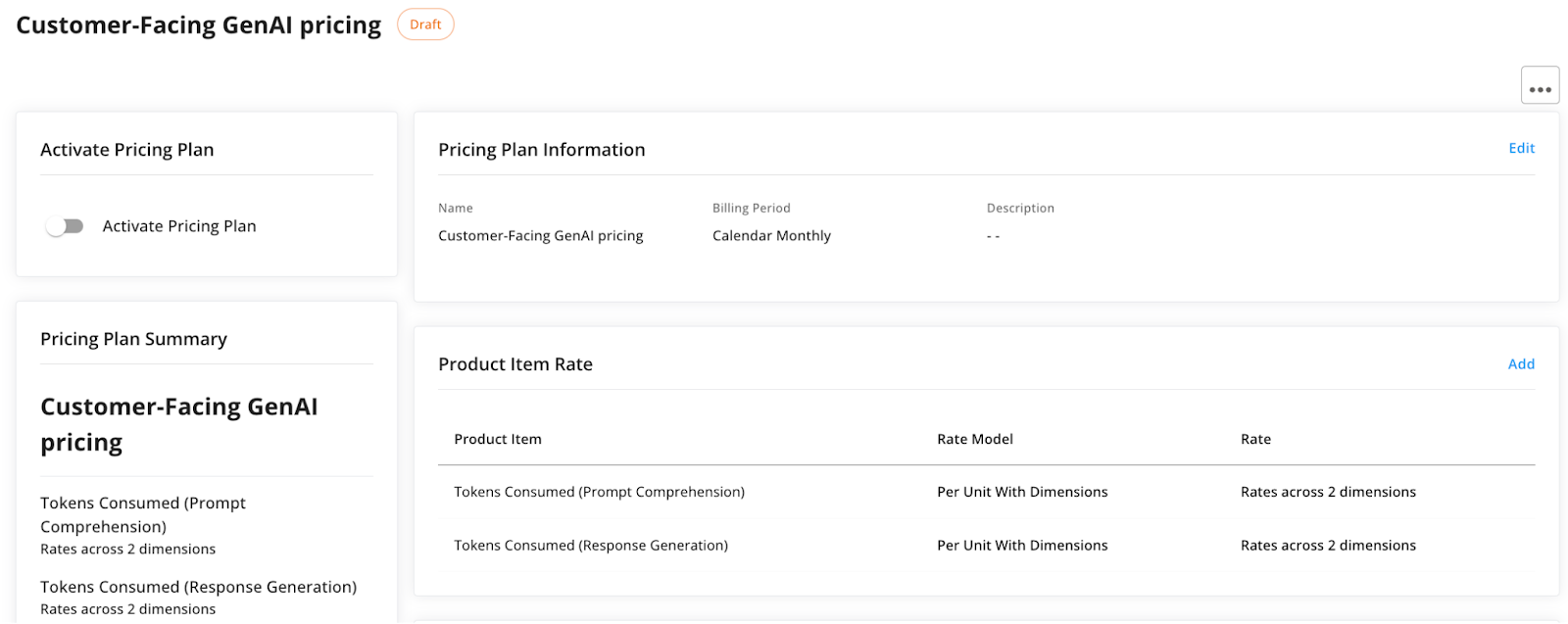
First, activate the pricing plans in Amberflo. This takes them out of ‘Draft’ mode and into the ‘Active’ state where they are locked to further changes and able to be associated with customers for invoicing.
You activate a pricing plan you’ve created for each tier by selecting the plan from the list of plans (from the Pricing Plans view on the main navigation menu), and clicking the toggle, shown in the top left of the screenshot below.
You can manually create customers in Amberflo and assign them a pricing plan. See AWS-style pay-as-you-go pricing for more information. You can also embed our UI widgets in your website or application to allow users to select their own plan - this will automatically create the Amberflo customer and assign them to a plan.
Step Five - Calculate internal costs by recreating OpenAI pricing in Amberflo
Next, create a separate pricing plan that exactly recreates OpenAI pricing. This will allow you to track internal costs at a per-customer or per-dimension level for deeper insights into usage patterns, account health, and granular margins.
Recall, OpenAI pricing can be found here.
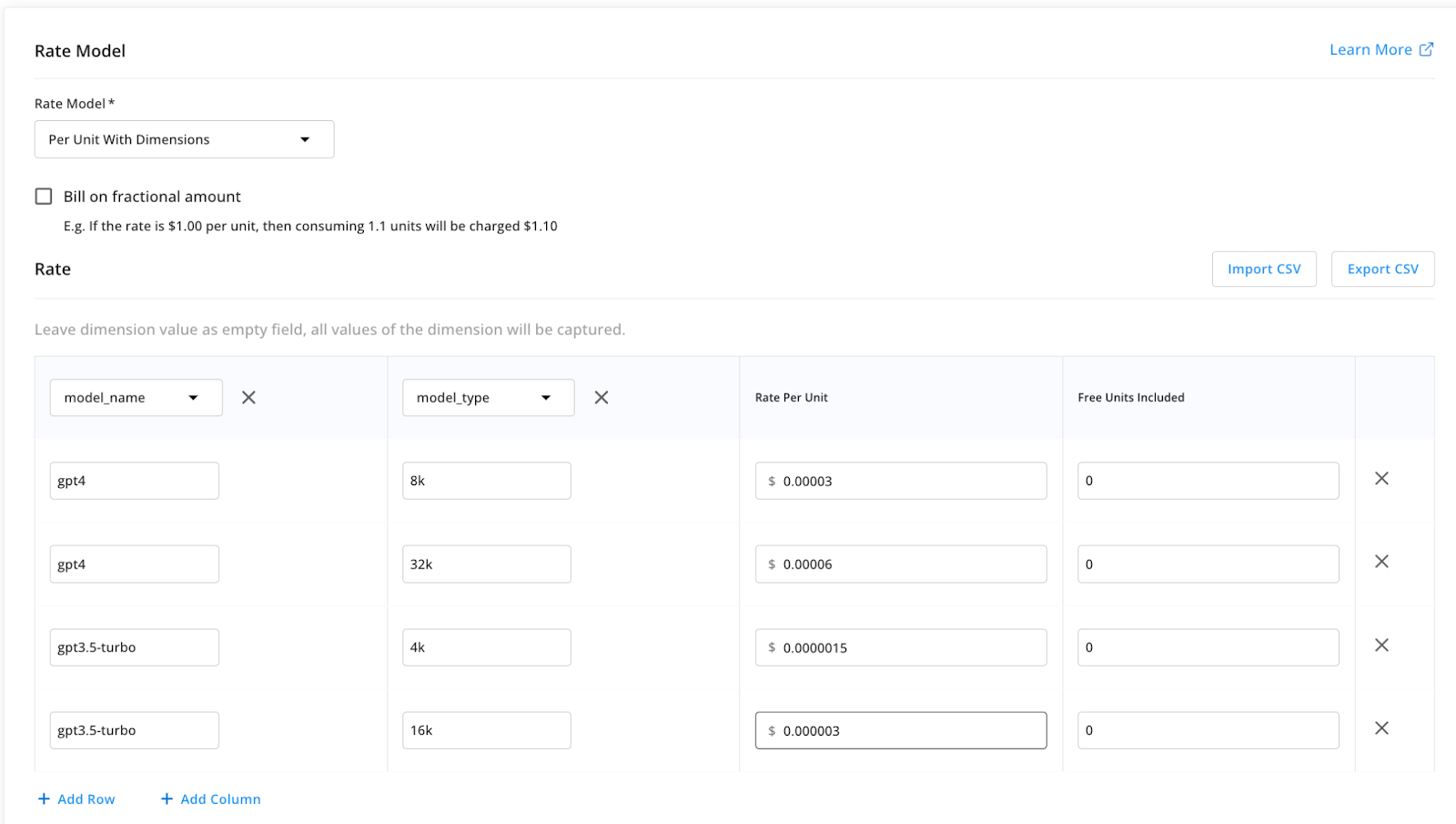
Similar to Step Three, create a pricing plan with two product items. Both will use the Per Unit with Dimensions rate model, however in this case the pricing plan will exactly mirror OpenAI’s per-token pricing.
Remember to add pricing for both the tokens consumed by the prompt comprehension (input) and the response generation (output). This pricing should exactly mirror that on OpenAI's public-facing website.
Step Six - Create a price model to compare customer-facing and internal pricing side-by-side
At this point, the customer-facing pricing is being applied to calculate the monthly billable amounts. The internal costs pricing plan can be applied on the same usage data to show internal costs and help calculate margins at a customer-level or product-level.
To accomplish this, we will create a price model that compares the customer-facing pricing with the internal pricing.
See the screenshot below for an example of the configuration:
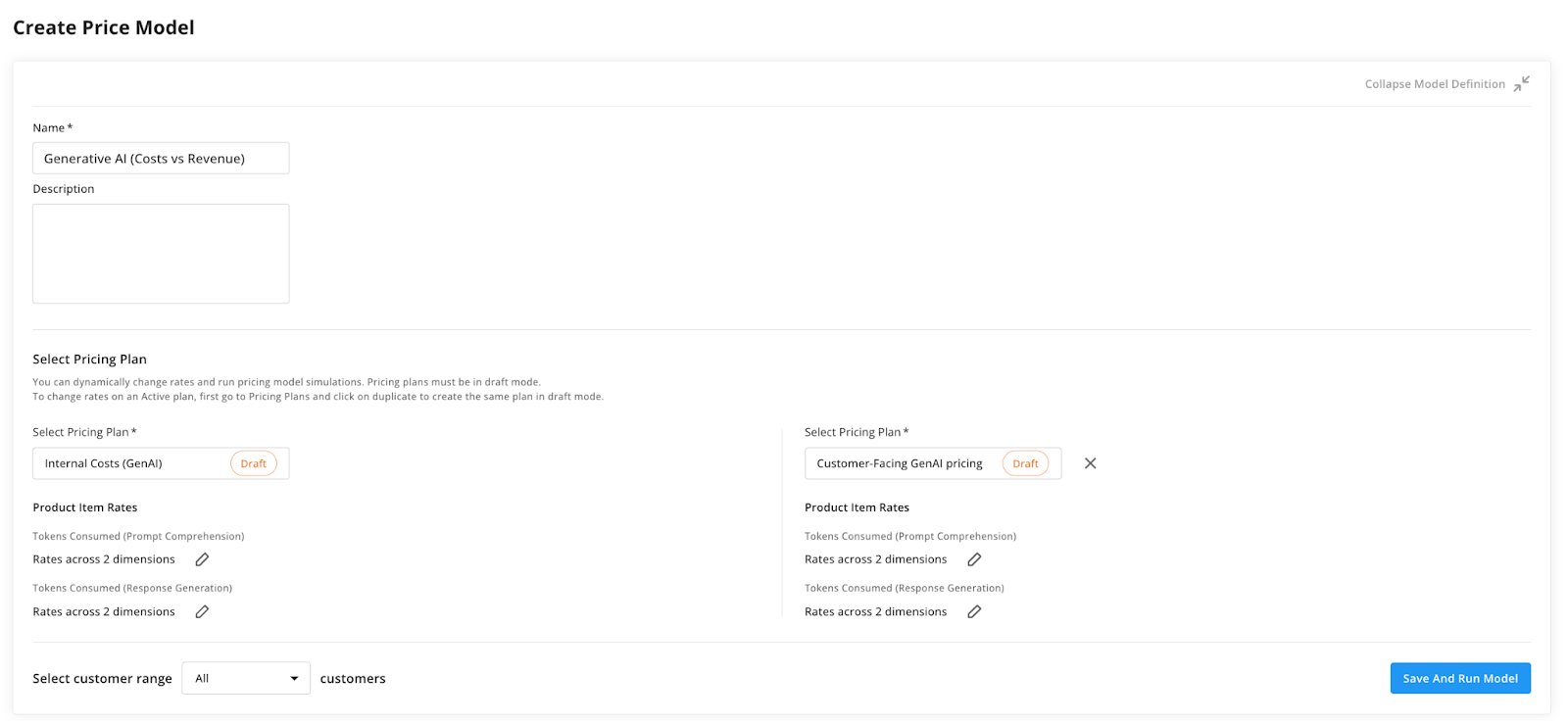
After saving and running the model on the live usage data from your system, you will be able to see a breakdown and comparison of the itemized costs and revenue, at a per-customer, per-product item, or even per-dimension level.
This is the level of intelligence and real-time insight that is needed to operationalize and monetize a generative AI service with usage-based pricing at your own business.
Tying it all together
Amberflo provides an end-to-end platform for customers to easily and accurately meter usage and operate a usage-based business. Track and bill for any scale of consumption, from new models in beta testing up to production-grade models with thousands of daily users. Amberflo is flexible and infrastructure-agnostic to track any resource with any aggregation logic.
Build and experiment with usage-based pricing models, prepaid credits, hybrid pricing, or long-term commitments to find the best model and motion to suit any unique business and customer base. Leverage real-time analytics, reporting, and dashboards to stay current on usage and revenue, and create actionable alerts to notify when key thresholds or limits are met.
Amberflo allows you to track, in real-time, at per-customer and per-dimension level granularity, the usage and revenue generated from that usage. Tracking real-time costs and revenue provides the insight and agility needed to respond to changing user behaviors, to control costs and ensure margins remain within acceptable bounds, and to ultimately scale usage and drive revenue.